【撰文:詹峻陽 】
隨著Google旗下DeepMind所研發的人工智慧(AI)系統AlphaGo所帶起的一波人工智慧熱潮,台灣沒有錯過。科技部長陳良基將2017年訂為台灣的「人工智慧元年」,從建立「人工智慧高速運算服務」、在台大、清大、交大、成大設立「AI創新研究中心」、打造中科與南科的「智慧機器人自造者基地」,到AI計畫的最後一塊拼圖「半導體射月計畫」,都是希望強化台灣半導體產業於人工邊緣智慧(AI Edge Intelligence)的核心技術競爭力和在前瞻半導體製程與人工智慧晶片系統研發。
邊緣智慧,AI應用的最後一哩路
事實上,許多具有傳感器的裝置早就存在我們的生活裡,如攝影機、相機、喇叭與麥克風等也在過去10年左右,數位化連上網路。但連結網路攝影機與網路連接儲存裝置(NAS)所組成的數位監視系統相較於過去閉路式、類比訊號的監視裝置,除了儲存資料數位化之外,在本質上並沒有太大的不同,一樣需要人監看、回放,並判斷實際現場狀況。但當人工智慧應用普及,影像辨識、語音辨識轉成文字不再遙不可及,網路攝影機或現場麥克風所傳回的資料都可即時透過自動辨識,判斷畫面中的物體,加上蒐集人臉資訊及現場收音,AI都足以自動綜合解讀更多現場狀況,讓安防業者不再需要配置人力長時間全神貫注監看,僅須排除異常狀態。
數位監視系統配上人工智慧應用,彷彿在機器中加上了靈魂,如果可透過人工智慧學習不同辨識內容組合的場景意義,並對應相應的處理機制,就賦予數位監視系統協助安防控制,真正達成智慧化。
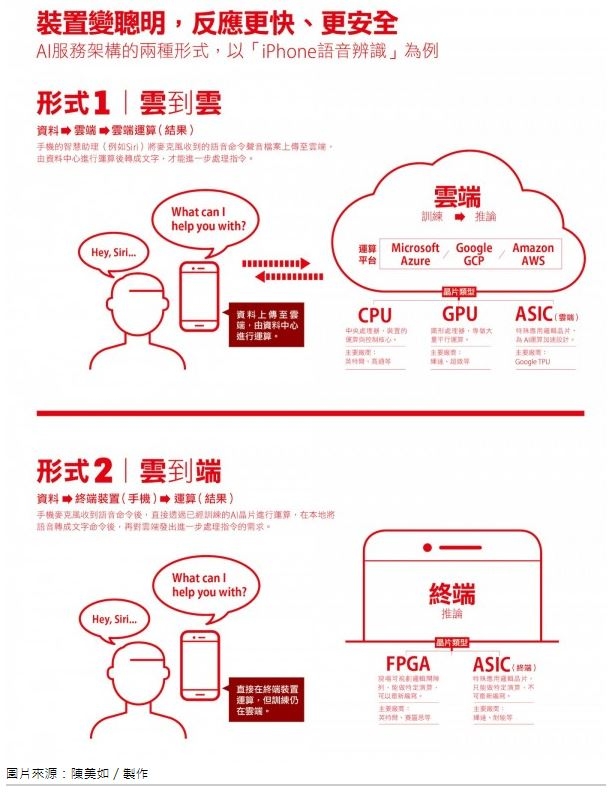
然而,要能夠讓攝影機進行影像辨識,除了可以將影像透過即時傳輸回主機上再進行計算判讀外,也可以想辦法透過攝影機上的處理器,直接計算進行辨識。前者需要占用大量網路傳輸資源,也有延遲時間的限制,但如果可以在攝影機裡加上適當設計、可節省電力的處理器與作業系統,直接現場計算辨識,不但可以省卻傳輸成本,也能減少辨識結果的延遲時間,加快即時反應。「邊緣智慧」就是指「在最終端裝置上的處理器與全套作業系統」,也可說是人工智慧落實到真實生活未來應用的最後一哩路。
從訓練到推論,晶片是最後一塊拼圖
然而對企業來說,深度神經網絡1(Deep Neural Networks,DNNs)所帶起的人工智慧浪潮,就如同遙遠的國度發生了大海嘯,要把如今相對成熟的圖像辨識、語音辨識或文本翻譯,放進真實環境做商業應用仍還有一段距離。
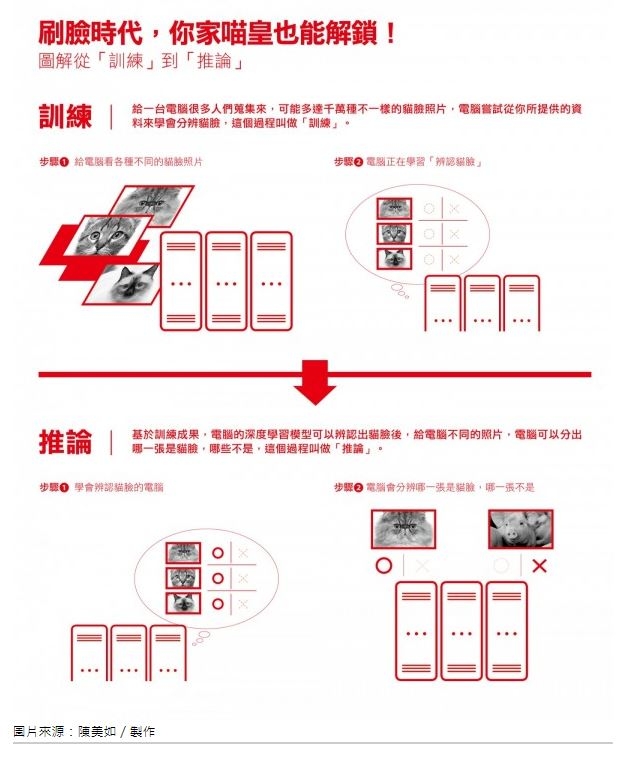
由於深度學習2的演算法與相關應用仍在快速演進中,無論是智慧城市、智慧零售、智慧音箱或無人車等實際的應用場景,仍在大量蒐集數據,讓深度學習演算法學習辨別這些資料特徵與模式的階段,這個系統過程稱為訓練(Training),讓電腦嘗試從我們所蒐集的資料來學習。
曾經走紅的萬物聯網讓科技產業認為,這就是未來的智慧樣貌,直到AlphaGo擊敗世界棋王,科技圈才發現人工智慧所帶來的「智慧服務」,才是真正賦予了萬物聯網的背後價值。
訓練的過程需要極大的運算量,以圖像辨識為例,要訓練電腦模型認識一種特定物體,例如花朵或貓咪,可能需要至少千張、多則超過百萬張各種不同角度、不同場景、不同光線下所拍攝的照片,因此這樣的運算往往在雲端或資料中心進行。如果要求同樣一個模型要能夠辨識各種不同品種的貓,除了需要更大數量的照片,更需要人工對這些照片中的貓咪品種先進行分類標注,再交給深度學習相關的演算法進行訓練,才能得到最終可應用的模型。
訓練是整個人工智慧應用裡,最耗計算資源的工作步驟,所以通常都會透過繪圖處理器(GPU)所特別擅長的平行運算來進行加速。尤其是現在最熱門、常超過百層、複雜度極高的深度神經網絡,都會希望使用特殊可針對大型矩陣運算做平行處理的特殊計算晶片,來加速訓練過程。然而,人工智慧的真實應用往往發生在終端,無論是圖像、影像、語音辨識或文本翻譯,透過深度學習所訓練出來的模型如果放在雲端,意味著每次應用發生時,終端首先要傳輸圖片、影像、語音或文本,等雲端判讀後再將結果回傳。就算網路頻寬再大、速度再快,這段傳輸與回傳過程都須占用資源、並造成反應時間延遲。
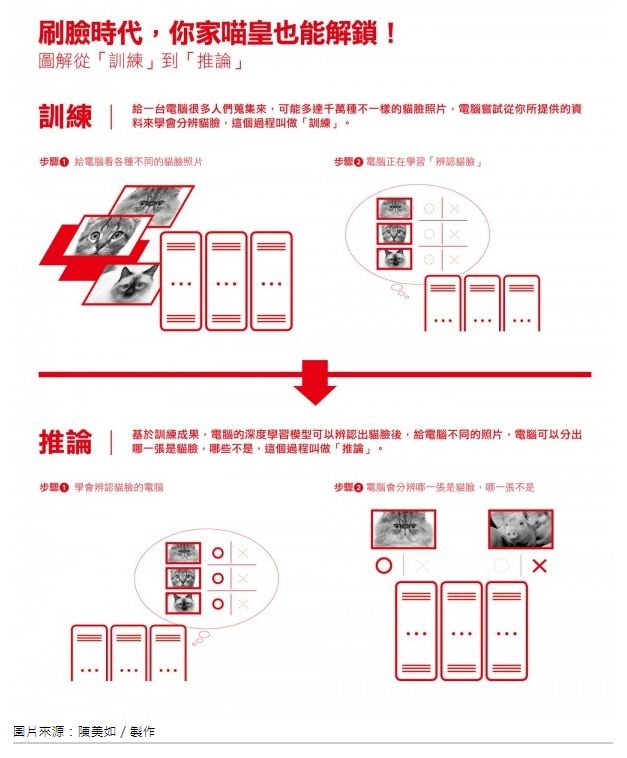
所以,能夠在終端接收實體資料,並快速預測回應的過程稱為推論(Inference)。對推論來說,在終端應用上減除那些對預測不必要的模型,或是合併對結果無足輕重的運算,來縮小計算規模非常重要。就算推論相對不消耗運算資源,但多數推論應用仍須特殊計算晶片加速來縮短反應時間,也就是說,若終端要能進行推論,每一台裝置上都將以晶片來加強能力。
中西巨頭投入AI晶片開發,郭台銘也要做
今年1月,新創數據平台CrunchBase所推出的2018年AI市場報告指出,亞馬遜、Google與微軟等網路公司已經主宰了企業AI這個市場,三巨頭分別推出的人工智慧即服務(AI as a Service),已經讓機器學習的新創難以獨立生存。企業AI需要資料中心級的大規模投資,提升每單位電力所能換來的計算量,用更小的空間就能帶來更多的計算,這是雲端服務商所追求的市場,也給了Google等科技巨頭除了GPU與CPU之外,開發專為資料中心進行深度學習加速晶片的好理由。
在Google以TPU這類特殊應用邏輯晶片(ASIC)提高人工智慧應用訓練能力的同時,雲服務業者也期望將推論應用門檻降低,讓推論能力滲透到更多終端應用,如此也可以回過頭來進一步拉高訓練需求。這也是為什麼除了雲端服務巨頭們如Facebook、蘋果,甚至中國的百度、阿里巴巴都紛紛宣布要發展自己的AI晶片,連鴻海董事長郭台銘都喊出:「半導體我們自己一定會做。」
無論是訓練或推論,深度學習所推起的人工智慧應用需求,無疑推動了許多公司評估各種晶片解決方案的可能性。「這將是百家爭鳴的盛會,是計算機架構與封裝技術的復興,我們將在接下來1年看到比過去10年更多、更有趣的計算機。」計算架構權威、加州大學柏克萊校區的榮譽教授大衛·帕特森(David Patterson)非常樂觀看待近來興起的運算晶片熱潮。陳良基也非常期待,台灣若能開發應用在各類智慧終端裝置上的關鍵技術與元件晶片,將可以使具有半導體製造、設計,並能夠整合終端裝置製造供應鏈的我們,再次居於世界領先地位。












